Elasticsearch 新手指南
 on [Unsplash](https://unsplash.com?utm_source=medium&utm_medium=referral)](https://cdn-images-1.medium.com/max/11520/0*a75ztDiDQX1fhNKE)
Elasticsearch 是一种支持非结构化数据的复杂聚合的分布式、可扩展的分析类搜索引擎。
类似于 NoSQL 数据库,Elasticsearch 是为处理非架构化数据格式并动态确定字段数据类型而创建的。它处理的主要数据格式是 JSON(Javascript Object Notation)文档。JSON schema-less 的数据格式使得数据存储变得很灵活,并且易于添加数据而无需管理或者创建数据关系。
然而,Elasticsearch 并不一定能作为 NoSQL 数据库使用。Elasticsearch 与 NoSQL 是有差别的,而且它自身也有一些局限性。例如,Elasticsearch 分布式系统在执行事务的时候会增加一层复杂性。尽管完成分布式事务也不是不可能,但为了简化流程还是尽可能避免使用它的分布式事务处理。
Elasticsearch 还会认为提供给节点的内存是足够的。因此它不擅长处理内存溢出。这就使得 Elasticsearch 相比于其他的数据存储系统鲁棒性更低。
Elasticsearch 常被用来作为其他类型数据库的辅助工具。记住 Elasticsearch 是为速度而生的这一点很重要。它是搜索和过滤文档的理想之选。
节点和集群
Elasticsearch 由多个节点构成(也叫做 Elasticsearch 实例),一组连接在一起的节点则被称为集群。同一个集群内的所有节点都知道集群内的其他节点的信息。集群内的每个节点都可以通过 HTTP 请求(POST, GET, PUT, DELETE)来执行增删改查操作。这种模式使得节点可以将客户请求转交其他节点来完成。
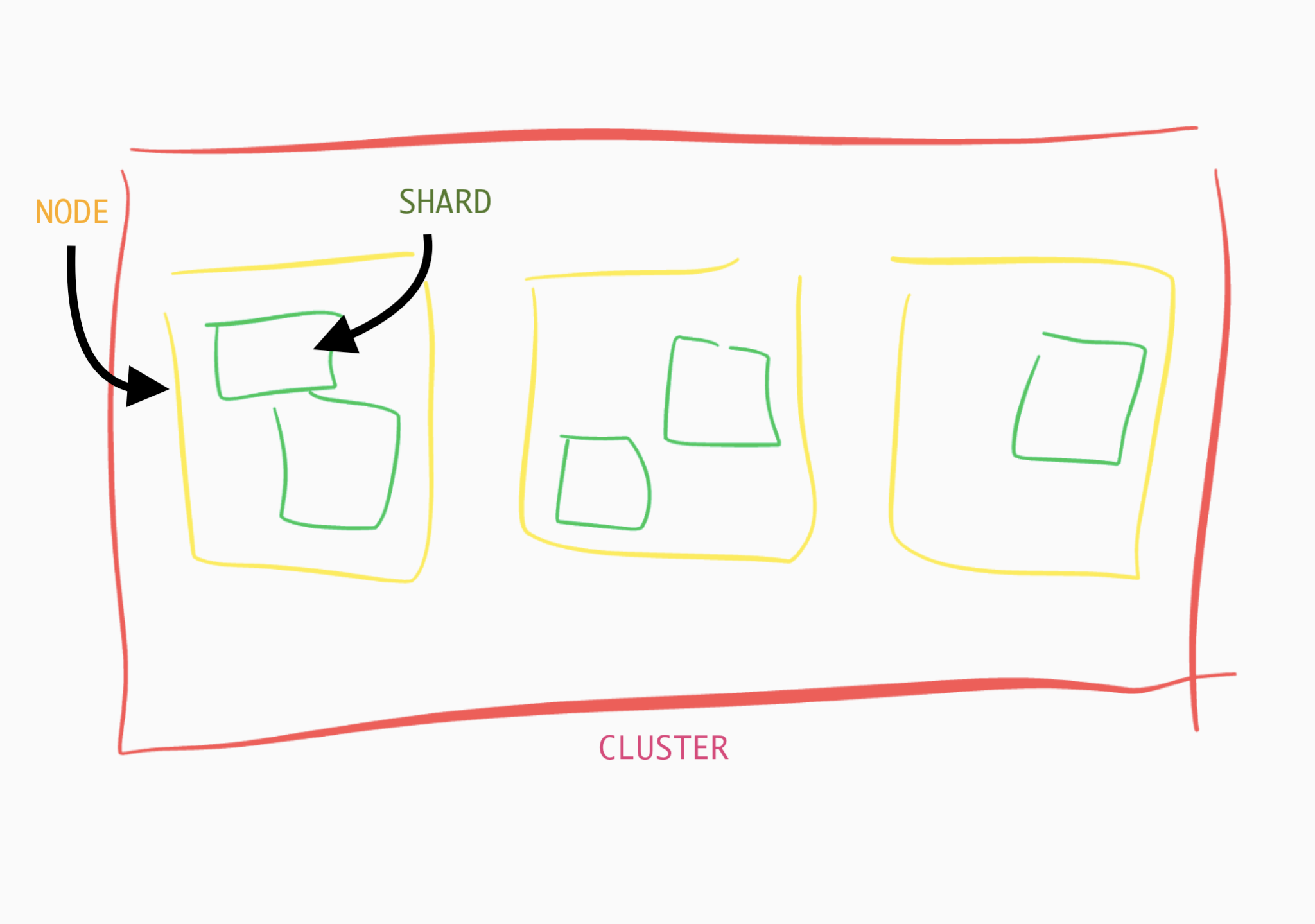
索引和分片
Elasticsearch 的索引有时候会被误认为跟关系型数据库中的索引是一样的。但是,理解它们之间的区别至关重要。Elasticsearch 索引是一组分片的集合,而文档则均匀分布在这些分片上的。如果没有特别说明,Elasticsearch 默认为每个索引分配 5 个主分片。上图可见这种分配模式。
例如,你可能会定义一个名为 products 的索引。这个索引里存在不同的产品文档,如下所示:
1 | [{ |
当文档被添加到一个索引时,Elasticsearch 会决定哪个分片用来装载这些文档。分片是均匀分布在集群内的节点上的。如果新的节点加入到集群中,Elasticsearch 将在集群里重新均匀地分配分片。
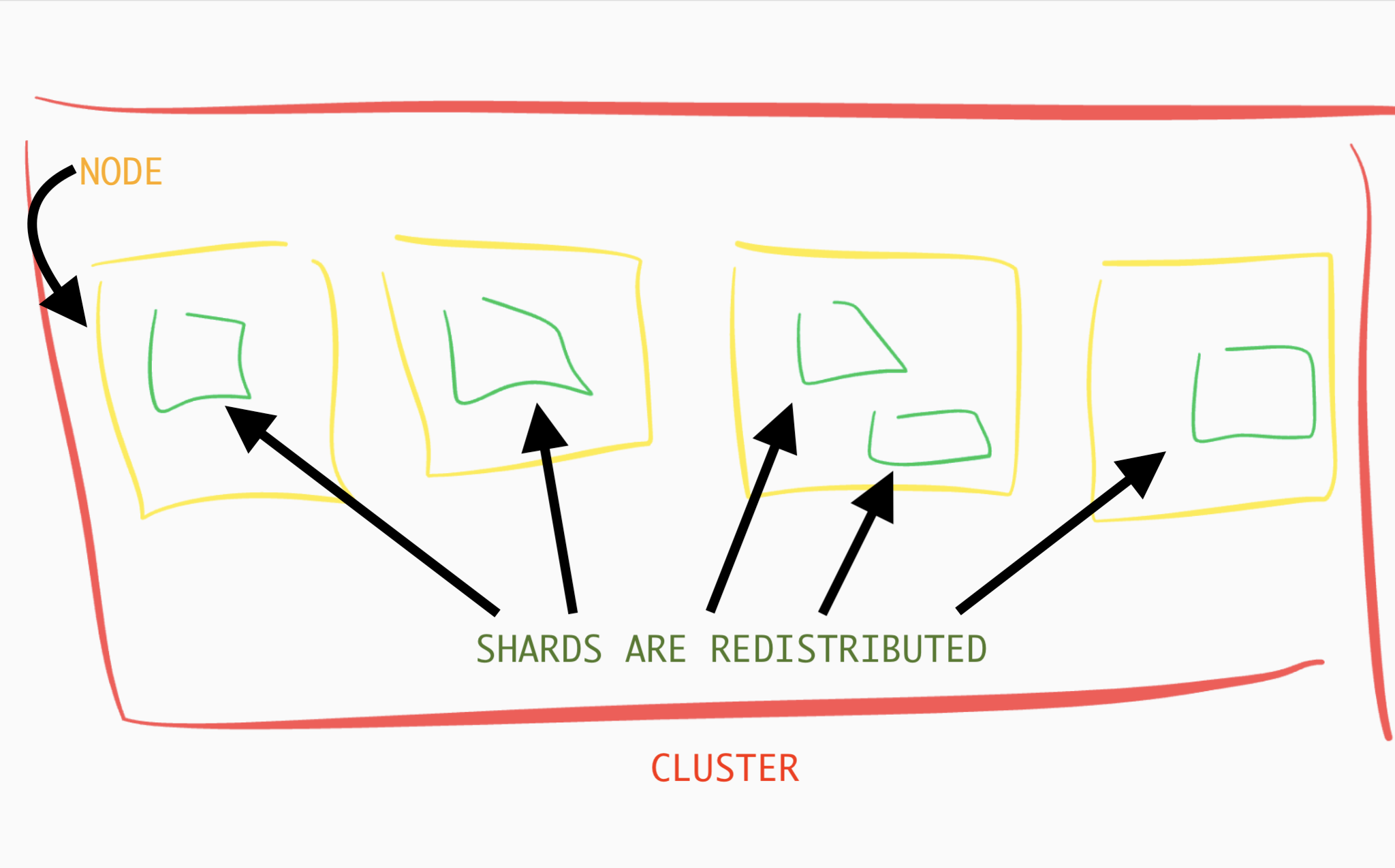
Elasticsearch 的 “活跃” 分片也值得提一下。活跃分片正如它的名字所表达的,指的是活跃着的保存有数据的分片。 如果文档不够多,不足以充分使用所有的分片,那么其中一些分片尽管是分配给这个索引的,也不会被认为是活跃的。稍后你将看到一个例子。
副本
副本是分片的一种类型,只不过它是用来提高搜索性能并作为主分片的备份的。一个完整的副本由 5 个副本分片组成。因此我们通常可以认为每个索引拥有一个副本。
副本分片可以作为可靠的故障转移,因为它们不会跟它所复制的数据被分配到同一个节点。如果你熟悉 RAID(冗余独立磁盘阵列),那副本分片跟它有些类似。数据被镜像拷贝到一个冗余的磁盘,在 Elasticsearch 里其实就是镜像拷贝到一个分片。并且由于分片在一个独立的节点上,如果含有主分片的节点故障了,副本仍然是可用的。而副本分片的节点和主分片的节点同时故障的风险相对较小。
阐明与 “关系型数据库” 的类比
Elasticsearch 理解起来可能会有点复杂。这些困惑主要是 Elasticsearch 团队在描述这些概念时所使用的一些不准确的类比造成的。在那以后,Elasticsearch 团队也试图解释这些误解。
大多数互联网上的资料都把一个索引和一个单独的关系型数据库做比较。那现在你可能会想,与其说索引像一个数据库,它难道不更像一张表吗?
你的理解是正确的,索引确实跟一张表类似。然而,在 Elasticsearch v.6 以及之前的版本中,一直有 类型 映射的概念。类型是用来表示一个索引内文档的类别的。举个例子,如果 “twitter” 是一个索引,那么我们可以描述 “twitter” 文档里的两种类型: “tweet” 和 “user”。 类型这个概念存在太多问题,因此我不会在这篇文章中深入探讨,但本质上,Elasticsearch 的类型是模仿了关系型数据库表。
我个人建议不要把 Elasticsearch 跟关系型数据库关联起来。这样只会让你更困惑,其实我也同样因此感到困惑。
安装和入门
如前文所述,与 Elasticsearch 交互的主要方式是通过 HTTP 请求(RESTFUL APIs)。 在本节内容里,作为入门,我们会回顾一些在 Elasticsearch 实例中创建索引的基本方法。
开始使用 Elasticsearch 之前,需要安装 Docker 并创建一个名为 data/elasticsearch 的文件夹。然后运行下面的 docker 命令下载 Elasticsearch 的 docker 镜像文件并启动 docker 容器。
1 | docker run --restart=always -d --name elasticsearch \\ |
现在你就可以通过 [http://localhost:9200](http://localhost:9200) 访问 Elasticsearch 所有的 API 了。
创建一个新索引
你可以用下面两种方法中的任意一种来创建文档,通过 PUT 请求或者 POST 请求。因为我要使用的是 Elasticsearch v.7 版本,所以我会避免提到与类型有关的话题。我会坚持使用 Elasticsearch 的默认类型 _doc 来操作索引和文档。
我们可以用如下方式创建一个空索引:
1 | PUT http://localhost:9200/products |
我们也可以通过在我们想要的索引中插入一个文档的方式来创建索引,如下所示:
1 | POST: http://localhost:9200/product/_doc/ |
上面的请求将产生如下响应报文:
1 | { |
在上面的响应报文里,每个插入的文档都有一个随机生成的识别码 _id。但是如果你想指定识别码,就需要把 POST 请求改为一个 PUT 请求,并如下所示在请求的末尾添加一个识别码:
1 | PUT: http://localhost:9200/product/_doc/1 |
再次回到上面的响应报文,我们注意到一共有 2 个分片,而其中一个分片在结果中显示是成功的。我在前文有简要的提及,活跃分片装载了数据,而副本分片装载了一份数据的拷贝。因此,这段响应报文告诉我们数据是从 2 个活跃分片 (其中一个是副本分片) 中的一个获取的。
我们可以通过调用 CAT (压缩并对齐文本) API 来验证分片数量,如下所示:
1 | GET http://localhost:9200/_cat/shards/product |
CAT API 是用来对 Elasticsearch 集群进行统计查询的。我们可以查询关于节点,集群,索引,模板以及其它的 Elasticsearch 特征。
上面的请求会产生如下结果:
1 | product 0 p STARTED 4 7kb 1xx.xx.x.x a6ffefa157e8 |
这段响应报文告诉我们在索引 product 里找到的分片 (在此它们都被标记为 0) 要么是副本 r, 要么是主分片 p,并且状态是 STARTED 或者 UNASSIGNED。 这段响应也告诉了我们分片里的文档数量,磁盘大小,IP 地址和节点 id。
要得到 CAT API 请求的完整列表,我们需要做如下请求:
1 | GET http://localhost:9200/_cat/ |
我推荐把这个请求保存到你易于访问的地方。因为这个 API 可以方便你学习 Elasticsearch 。
搜索索引
Elasticsearch 强大的搜索功能是很难用几个段落就总结完的。我这里会提供 2 个基本的搜索功能以便你们入门: 获取索引里的所有文档和通过识别码获取一个文档。 我会在其他的文章里讨论更复杂、更有趣的搜索查询。
我们可以用下面的请求获取一个索引里的全部文档:
1 | GET http://localhost:9200/product/_search |
然而,在默认情况下,Elasticsearch 每次只会返回 45 个文档。不过我们可以在查询字符串中提高这个限制值,正如下面请求里的 size 字段:
1 | GET http://localhost:9200/product/_search?size=100 |
通过识别码获取单一文档跟上文提到的添加一个文档的请求方法很类似,只不过要将 POST 请求改成 GET 请求,如下所示:
1 | GET http://localhost:9200/product_entity/_doc/1 |
结语
Elasticsearch 是一个强大的分析类搜索引擎。但是它操作起来会很复杂。
我在本文介绍了一些帮助你们入门的基础概念。但我还是强烈推荐你们浏览 Elasticsearch v.7.9 或更高版本的文档 以及 Elasticsearch 博客 来加深和拓展你的理解。
如果发现译文存在错误或其他需要改进的地方,欢迎到 掘金翻译计划 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 本文永久链接 即为本文在 GitHub 上的 MarkDown 链接。
掘金翻译计划 是一个翻译优质互联网技术文章的社区,文章来源为 掘金 上的英文分享文章。内容覆盖 Android、iOS、前端、后端、区块链、产品、设计、人工智能等领域,想要查看更多优质译文请持续关注 掘金翻译计划、官方微博、知乎专栏。